第2回 データレコードとファイルアクセスの種別
副題:データベースはどのように蓄えられるか
・データベースに蓄えられるデータ : 通常のファイルと同様に、ハードディスクやCD−ROMなどの補助記憶装置に格納される
ただし、どのような秩序のもとに格納しておくかによって、取り出しやすさに違いが出てくる。
データベースを作る側に立った場合の、システムの内側でなされているノウハウを学ぶ。
これを学べば、使うときも違った視点が出てくる。
1 物理レコードの構成
物理レコード = 計算機が1回の入出力命令で読み出したり、書き出したりするデータの単位。「ブロック」とも。
ページ = 物理レコードの大きさは可変長の場合もあるし、固定長の場合もあるが、ここでは固定長のものをこう呼ぶ。
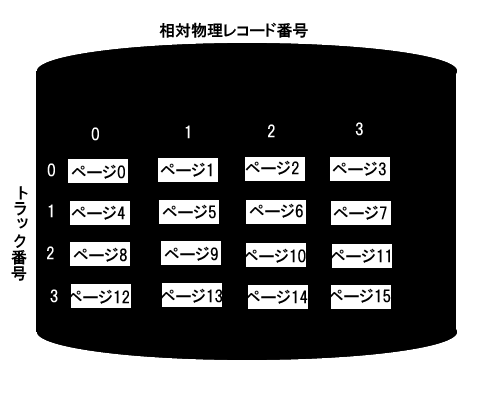
各ページが補助記憶装置に格納されている様子はこのようになる。
論理レコード = 計算機でデータをファイルに蓄積する場合の、利用者にとって意味のある、一連のデータ単位。
単にレコードと言った場合、物理レコードではなく、これをさす。
物理レコード = 論理レコードA + 論理レコードB +・・・・・・+論理レコードN
レコード = フィールドA + フィールドB +・・・・・・+フィールドN
フィールドの構成の仕方の3種
(a)各フィールドが固定長の場合
(フィールドによっては、余分なスペースを確保しておく必要がある)
2260 |
ヤマダ カズオ | 22 | オタルシ ミドリチョウ |
固定長の長さを超えると越えた部分を格納できない点、固定長を長く取りすぎると無駄が生じやすい点が短所だが、処理はしやすい。
(b)各フィールドが可変長で、フィールド長も記憶する場合
(フィールドごとにフィールド長を記憶するので、その分だけ記憶域が無駄になるが、余分のスペースを蓄えなくてすむ)
| 04 | 2260 | 09 | ヤマダ カズオ | 02 | 22 | 12 | オタルシ ミドリチョウ |
(a)の短所をカバーできることが長所だが、処理する際に、レコードごとに長さを見る必要がある。
(c)各フィールドが可変長で、フィールド長とフィールド名を記憶する場合
(実際にはフィールド名は内部コードに変換されて記憶する。あるフィールドの値がないとき、そのフィールドは蓄積されない)
| 従業員番号 | 04 | 2260 | 氏名 | 09 | ヤマダ カズオ | 住所 | 12 | オタルシ ミドリチョウ |
値が設定されないと、されていないフィールドの格納領域を無駄にしないという長所があるが、(b)の短所に加え、
フィールドごとに何のフィールドか判断する必要がある。
データ圧縮 = 無駄な情報を取り去って蓄積データを減らすこと。
−前後の差異だけ記憶。コード化。
−圧縮があれば解凍も必要!
2 レコードを早く呼び出す方法
この日は、
Q1.10枚の年賀状を持っている。ある特定の人物の年賀状を探したい。どうするか?
Q2.100枚の年賀状を持っている。ある特定の人物の年賀状を探したい。どうするか?
Q3.1000枚の年賀状を持っている。ある特定の人物の年賀状を探したい。どうするか?
という演習をやりました。
現在はハッシングとインデックスの二つがあるそうで、それ以外でいいものが思いついたら、チューリング賞がもらえるとか。
2.1 ハッシング
キー = レコードを識別するフィールド。異なるレコードで同一の値をとることはなく、このフィールドの値さえわかれば、
レコードを一意に特定可能
メインアイディア:キーkに変換fを施して、格納ページpを得る。
p=f(k)
f : ハッシュ関数。キーをページ総数で割ったあまりを使うのが普通。
ページがレコードであふれたら、ほかのページに格納するためのルールも決めておく。
格納が決まれば検索も決まる。
2.2 インデックス
レコードのキーからそのレコードの所在番地を与える。