平均と標準偏差はそれぞれ次のようになります。
箱・つくりおき
平均 73.00 標準偏差 10.77(10.7703…)
箱・注文
平均 73.67(73.6666…) 標準偏差 11.18(11.1753…)
紙・つくりおき
平均 67.33(67.3333…) 標準偏差 10.78(10.7806…)
紙・つくりおき
平均 73.13(73.1333…) 標準偏差 10.87(10.8680…)
表にすると次のようになります。
| 箱 | 紙 | |||
| つくりおき | 注文 | つくりおき | 注文 | |
| 平均点 | 73.00 | 73.67 | 67.33 | 73.13 |
| 標準偏差 | 10.77 | 11.18 | 10.78 | 10.87 |
それでは、具体的に検定をしましょう。
今回のデータも、要因が2つあります。よって分散分析-二要因-をおこないます。
またこの点数は、条件ごとに違う人によって評価されたパターンではなく、全ての条件において一人が評価した点数です。
つまり「被験者内」データ、t検定でいう「対応あり」データです。
そのため前の分散分析-二要因-よりも計算が少し複雑になります。
前の分散分析-二要因-は、まず

これを計算しました。今回の被験者内における分散分析も基本的にはこれと同じですが、今回の全分散は次のようになります。
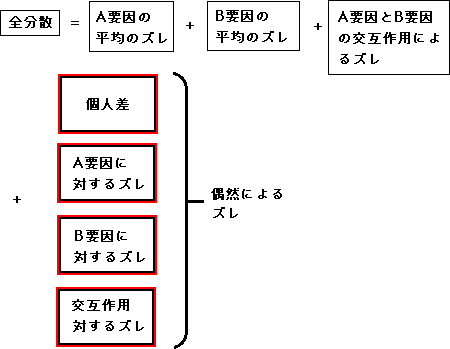
偶然によるズレの項目が個人差、A要因の偶然のズレ、B要因の偶然のズレ、交互作用の偶然のズレの4つに分けられます。それぞれのF比の分母は、それぞれの偶然によるズレで計算することになります。
被験者内の検定では、それぞれの要因や交互作用の偶然のズレを求めてF比を求めるので、検定力が高くなります。